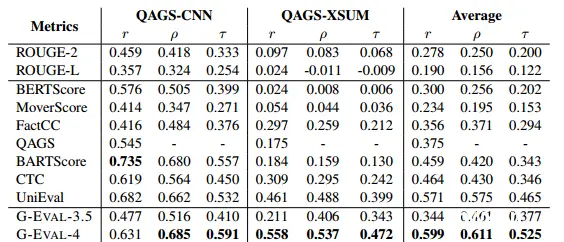
自然语言生成(NLG)系统生成的文本质量难以自动测量。传统的参考指标,如BLEU和ROUGE,已被证明与人类判断的相关性相对较低,特别是对于需要创造力和多样性的任务。最近的研究建议使用大型语言模型(llm)作为NL...
浏览 58 次 标签: G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment